OceanBase 支持多种类型语句的并行执行。在本篇博客中,我们将根据并行执行的不同类别,分别详细阐述:并行查询、并行数据操作语言(DML)、并行数据定义语言(DDL)以及并行 LOAD DATA 。
《并行执行系列》并行执行系列的内容分为七篇博客,本篇是其中的第四篇。
| 一 | 并行执行概念 |
| 二 | 如何手动设置并行度 |
| 三 | 并行执行线程资源管理方式 |
4.1 并行查询
你可以在下面几种场景里使用并行查询:
- select 语句,以及 select 子查询
- DML 语句(INSERT,UPDATE,DELETE)的查询部分
- 外表查询
并行查询的决策分为两部分:
- 决定走并行查询。如果查询中使用了 PARALLEL HINT,SESSION 上开启了并行查询,或TABLE 属性指定了并行,那么将会开启并行查询。
- 决定并行度。并行查询中,每个 DFO 的并行度可以不一样。
- 对于基表扫描或索引扫描 DFO,其并行度由 PARALLEL HINT、SESSION 并行属性,或TABLE 属性来决定。
- 对于基表扫描或索引扫描 DFO,如果运行时检测到它访问的数据不足一个宏块,那么它的运行时并发度会被局部自动降低。
- 对于 JOIN 等中间节点,其 DFO 并行度继承左孩子 DFO 的并行度。
- 部分 DFO 不允许并行执行(如计算 ROWNUM 的节点),那么他们的并行度会被强制设为 1。
4.2 并行 DML
大部分场景下,可以使用并行 DML (Parallel DML,简称 PDML)加速数据导入、更新、删除操作。
4.2.1 DML 并行度
DML 的并行度和查询部分的并行度一致。开启并行 DML 时,查询部分总是自动开启并行。读出的数据会根据待更新表的分区位置做重分布,然后由多个线程并行 DML,每个线程负责若干个分区。
并行度和目标表的分区数之间有倍数关系时,一般可以达到最佳性能。当并发度高于分区数时,会有多个线程处理同一个分区的数据;当并发度低于分区数时,单个线程可能处理多个分区的数据,并且每个线程处理的分区不重合。当并行度大于目标表分区数时,建议并行度是分区数的整数倍。
一般来说,同时向一个分区插入数据的线程数不要超过 4 个,超过这个值后扩展性并不好,日志同步会成为瓶颈,另外还有一些分区级别的锁同步开销。当并行度小于目标表分区数时,建议分区数是并行度的整数倍。这样,每个线程处理的分区数差不多,可以避免插入工作量倾斜。
4.2.2 索引表处理策略
并行 DML 支持自动维护索引表。
当索引表为本地索引时,并行 DML 在更新主表时,存储层会自动维护本地索引。
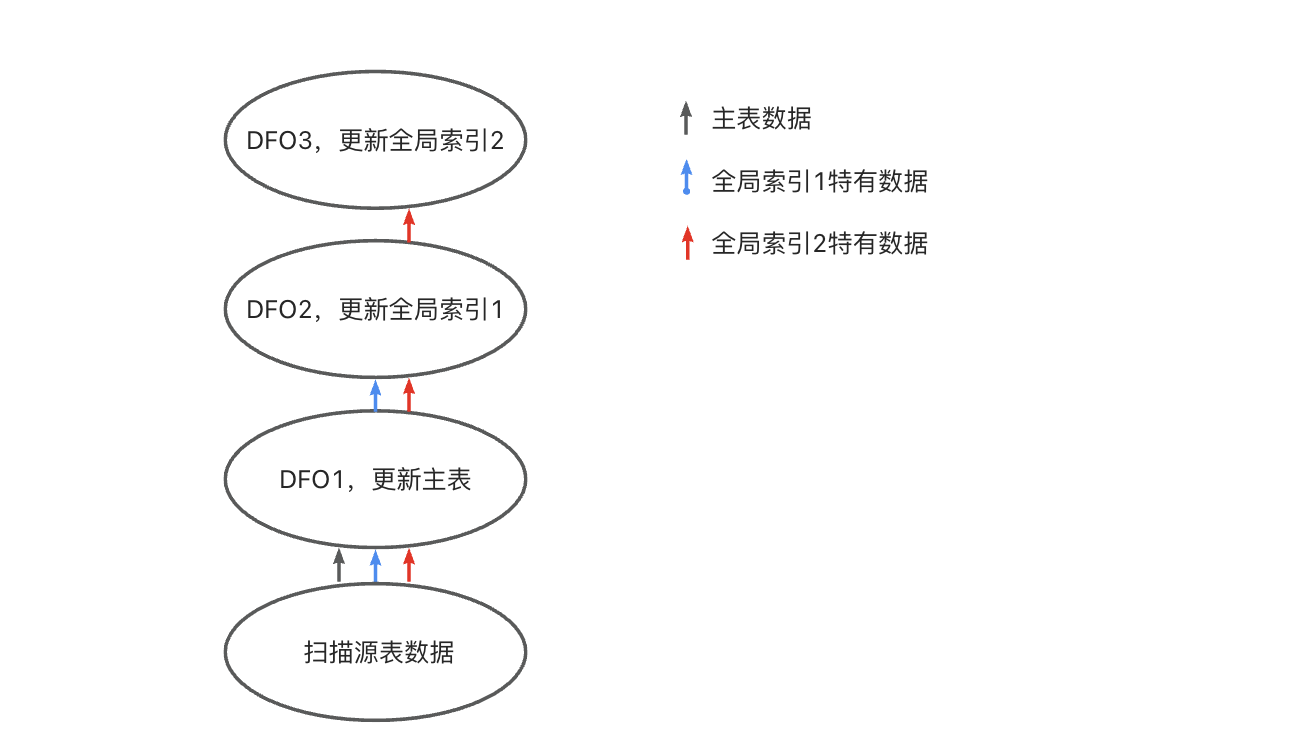
当索引表为全局索引时,并行 DML 框架会生成特定的计划来维护全局索引。假设有两个全局索引,处理流程如下:
- 首先,会用 DFO1 更新主表;
- 然后,DFO1 将全局索引1、全局索引2需要的数据发给 DFO2,用 DFO2 更新全局索引表1;
- 最后,DFO2 将全局索2引需要的数据发给 DFO3,用 DFO3 更新全局索引表2。
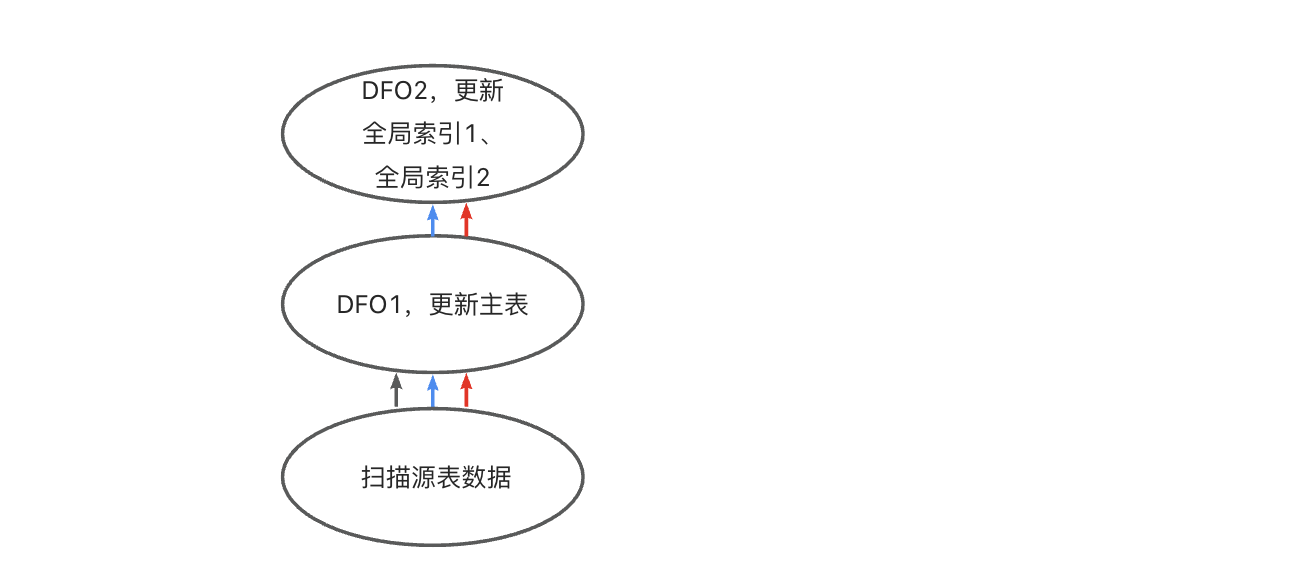
以上策略对所有 INSERT、DELETE、UPDATE 语句有效,对于 MERGE 语句,处理方式略有不同,所有的索引维护操作会集中到一个 DFO 中处理,如下图所示:
- 首先,会用 DFO1 更新主表;
- 然后,DFO1 将全局索引1、全局索引2需要的数据发给 DFO2,DFO2 内部会逐个完成全部全局索引的维护操作。
4.2.3 更新分区键的处理策略
对于 UPDATE 语句来说,当主表或全局索引表的分区键被更新时,需要把旧数据从旧分区中删除,然后把新数据插入到新分区中。这个过程通常被称作 row movement。
当发生 row movement 时,需要将 UPDATE 操作拆分成两步操作:先 DELETE,然后 INSERT。具体地,会将出现 row movement 的 UPDATE DFO 拆分成两个 DFO,第一个 DFO 负责 DELETE,第二个 DFO 负责 INSERT。并且,为了避免主键冲突,必须确保 DELETE DFO 完全执行完成后才能开始执行 INSERT DFO。
4.2.4 事务处理
OceanBase 并行 DML 和普通 DML 语句一样,完全支持事务处理。并行 DML 语句可以和其它查询语句一起出现在同一个事务中,执行完成并行 DML 语句后无需立即提交事务,就可以在后继的查询语句中读取到 DML 语句的结果。
在 OBServer v4.1 版本之前,当并行 DML 执行时间超长时,需要给租户配置项 undo retention 设置合适的值,否则可能发生 -4138 (OB_SNAPSHOT_DISCARDED) 错误,导致 SQL 在内部反复重试,直至超时。undo retention 字面意思是 Undo 的保留位点,即从当前时间回溯多长时间的 Undo 日志是保留下来的。对于 OceanBase 数据库来说,是将该时段的所有数据多版本保留下来。当并行 DML 执行时间超过 undo retention 设定的时间时,多版本数据可能被淘汰,当 DML 中的任何后继操作试图访问淘汰的多版本数据时,就会触发 OB_SNAPSHOT_DISCARDED 报错。undo retention 的默认值是 30 分钟,这意味着在默认情况下,如果并行 DML 语句 30 分钟内不能执行完成,无论语句的超时时间设定为多少,语句都可能执行超时并报错。一般来说,如果业务中的最长并行 DML 的执行时间为 2h 时, undo retention 可以设置为 2.5h。undo retention 不能随意设置为极大值,那会导致多版本数据无法回收,打爆磁盘。
从 OBServer v4.1 版本起,并行 DML 的执行不再依赖 undo retention 设定。多版本数据会根据事务版本号回收,只要事务还活跃,事务对应的版本号能读到的内容就不会回收。不过,数据盘满的场景是例外,此时还是会强行回收多版本数据,并行 DML 会收到 OB_SNAPSHOT_DISCARDED 报错,并自动重试整个 SQL。
4.2.5 旁路导入
当内存空间不足时,并行 DML 容易报告内存不足错误。没有走旁路导入路径的并行 DML,数据首先会写入 Memtable,然后通过转储、合并写入磁盘。因为并行 DML 写入数据到 Memtable 的速度极快,当写入速度快过转储速度时,内存就会不断增长,最终触发内存不足报错。
为了解决这个问题,OceanBase v4.1 的存储层提供了旁路导入功能。当并行 DML 使用旁路导入功能执行 INSERT 语句时,数据会绕过 Memtable 直接写入磁盘,不仅避免了内存不足的问题,而且还能提升数据导入性能。
用户通过 APPEND HINT 开启旁路导入功能。旁路导入开始前,要求提交上一个事务,并且设置 autocommit = 1。在 v4.2 版本中,旁路导入功能必须配合并行 DML 才能正常工作,如果没有通过 HINT 或 session 开启并行 DML,则旁路导入的 HINT 会被自动忽略。语法示例如下:
set autocommit = 1;
insert /*+ append enable_parallel_dml parallel(3) */ into t1 select * from t2;预计在未来版本中,旁路导入功能会放松对事务的要求,可以出现在事务中的任意位置。
4.2.6 无法并行的 DML 操作
为了保证正确的 DML 语义,如下场景中,查询部分可以并行,但 DML 部分无法并行:
- 如果目标表包含 local unique index,则 DML 部分不可并行,查询部分依然可以并行
- INSERT ON DUPLICATE KEY UPDATE 语句的 DML 部分不可并行
- 如果目标表包含 Trigger、外键,则 DML 部分不可并行
- 如果 MERGE INTO 语句的目标表中包含 global unique index,则 DML 部分不可并行
- 如果 DML 启用了 IGNORE 模式,则 DML 部分不可并行
如果发现 DML 没有走并行,可以通过 explain extended 来查看 Note 字段,确定未走并行的原因。
4.2.7 Row Movement 操作
当更新分区表的分区键时,可能使数据从一个分区搬迁到另一个分区。在 Oracle 模式下通过下面的命令可以禁止数据跨分区搬迁:
create table t1 (c1 int primary key, c2 int) partition by hash(c1) partitions 3;
alter table t1 disable row movement;
OceanBase(TEST@TEST)>update t1 set c1 = c1 + 100000000;
ORA-14402: updating partition key column would cause a partition change但是,并行 DML 会忽略表的 row movement 属性,总是允许更新分区键。
4.3 并行 DDL
支持并行执行的 DDL 语句包括:
- CREATE TABLE AS SELECT
- ALTER TABLE
- CREATE INDEX
4.3.0 原理
所有并行 DDL 都是通过特定的 Parallel DML 完成。例如,创建索引本质是创建一个索引空表,然后并行地从主表查询出索引列数据,最后并行地插入到索引表中。
4.3.1 通过 HINT 指定并行度
目前(v4.2)仅 CREATE INDEX 语句支持通过 PARALLEL HINT 开启并行,其余 DDL 都只支持 SESSION 变量和 TABLE PARALLEL 属性来开启。
CREATE /*+ PARALLEL(3) */ INDEX IDX ON T1(C2);4.3.2 通过 SESSION 变量指定并行度
上述所有 DDL 语句都支持通过 SESSION 变量来指定并行度。指定并行度后,该 SESSION 上的所有 DDL 都自动按照该并行度并行执行,并且查询部分和修改部分都使用相同的并行度。
SET _FORCE_PARALLEL_DDL_DOP = 3;
CREATE TABLE T1 (C1 int, C2 int, C3 int, C4 int);
CREATE INDEX IDX ON T1(C2);-- v4.2 中,CREATE TABLE AS SELECT 开并行,
-- 用的是 “SET _FORCE_PARALLEL_DML_DOP”
-- 而不是 “SET _FORCE_PARALLEL_DDL_DOP”
-- 后继版本可能会修改成后者
SET _FORCE_PARALLEL_DML_DOP = 3;
CREATE TABLE T1 (C1 int, C2 int, C3 int, C4 int);
CREATE TABLE T2 AS SELECT * FROM T1;4.3.3 通过表 PARALLEL 属性指定并行度
本节内容实测并没有走并行,需要跟进是否符合设计。验证方法:
select plan_operation, count(*) threads from oceanbase.gv$sql_plan_monitor where trace_id = last_trace_id() group by plan_line_id, plan_operation order by plan_line_id;
DDL 相关表上有 PARALLEL 属性时,可以使用 SET 语句设定 SESSION 变量来开启并行执行。例如:
SET _ENABLE_PARALLEL_DDL = 1;
CREATE TABLE T1 (C1 int, C2 int, C3 int, C4 int) PARALLEL = 3;
CREATE INDEX IDX ON T1(C2) PARALLEL = 2;-- v4.2 中,CREATE TABLE AS SELECT 开并行,
-- 用的是 “SET _ENABLE_PARALLEL_DML”
-- 而不是 “SET _ENABLE_PARALLEL_DDL”
-- 后继版本可能会修改成后者
SET _ENABLE_PARALLEL_DML = 1;
CREATE TABLE T1 (C1 int, C2 int, C3 int, C4 int) PARALLEL = 3;
CREATE TABLE T2 PARALLEL 2 AS SELECT * FROM T1;4.3.4 优先级
如果同时指定了 PARALLEL HINT、FORCE SESSION PARALLEL、表级 PARALLEL 属性中的两个或多个,那么它们的优先级如下:
PARALLEL HINT 优先级 > FORCE SESSION PARALLEL 优先级 > 表 PARALLEL 属性优先级
4.3.5 旁路导入
CREATE INDEX 语句无论是否开启并行,总是会走旁路导入(Direct Write,Bypass memtable)。
CREATE TABLE AS SELECT 语句目前(v4.2)还不支持旁路导入功能,如果数据量比较大,建议先建立空表,然后使用并行 DML 旁路导入模式并行插入。
4.4 并行 LOAD DATA
LOAD DATA 的实现不是基于并行 DML,它的实现方式是:先用多个线程并行切分 csv 文件,拼成多个 insert 语句,然后用一定的并发度分发执行这些 insert 语句。
LOAD DATA /*+ parallel(2) */ infile "test.csv" INTO TABLE t1 FIELDS TERMINATED BY ',' ENCLOSED BY '"';上述语句中,PARALLEL 选项指定加载数据的并行度,如果没有指定 PARALLEL HINT,则默认以 PARALLEL 为 4 来并行执行 LOAD DATA。 PARALLEL 建议取值范围是 [0, 租户的最大CPU数]。
4.5 局部无法并行的场景
- 最顶层 DFO 无需并行,它负责和客户端交互,以及执行最顶层无需并行的部分操作,如 LIMIT、PX COORDINATOR 等
- 包含 TABLE UDF 时,含该 UDF 的 DFO 只能串行执行,其余部分依然可以并行